¶ Usage Environment
Banana Pi RK3588 developemnt board design:
Rockchip RK3588 design Banana Pi BPI-M7 AI SBC design
Rockchip RK3588 design Banana Pi BPI-AIM7 Core board fully compatible with Jetson Nano/TX2 NX
Rockchip RK3588 design Banana Pi BPI-W3 LGA core board kit
Rockchip RK3588 design BPI-RK3588 core board and kit Introduction Core boards
Rockchip RK3576 design Banana Pi BPI-M5 Pro AI SBC design
Rockchip RK3576 design Banana Pi BPI-CM5 Pro AI Computer module design
Source Code repository: https://github.com/ArmSoM/rknn-llm
yotube video demo: https://www.youtube.com/watch?v=y1BLwYxFQ-4
¶ Introduction to RKLLM
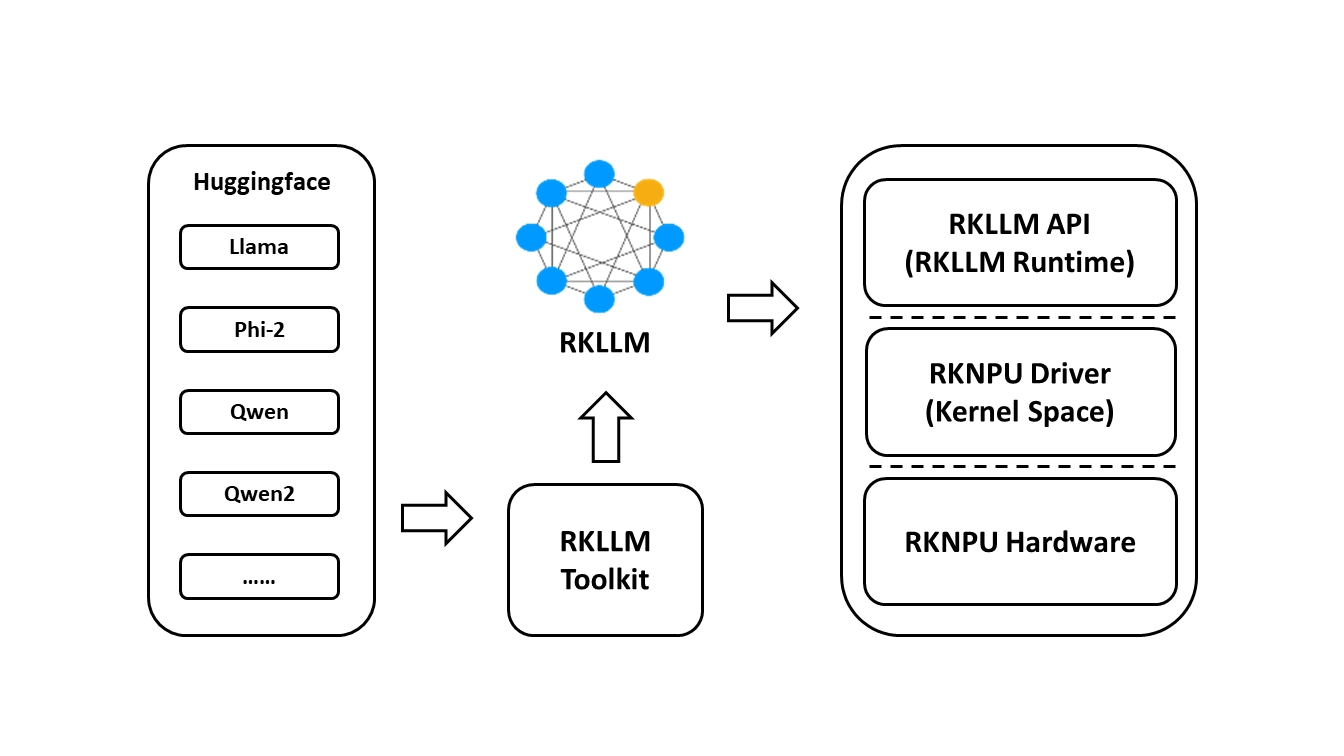
RKLLM software stack can help users to quickly deploy AI models to Rockchip chips. The overall framework is as follows:
¶ Introduction to RKLLM Toolchain
Overview of RKLLM-Toolkit Features:
RKLLM-Toolkit is a development suite provided to users for quantization and conversion of large language models (LLMs) on computers. Through the Python interface provided by this tool, users can easily accomplish the following tasks:
-
Model conversion: Supports converting Hugging Face format LLMs to RKLLM models. Currently supported models include LLaMA, Qwen/Qwen2, Phi2, etc. The converted RKLLM models can be loaded and used on the Rockchip NPU platform.
-
Quantization: Supports quantizing floating-point models to fixed-point models. Currently supported quantization types include w4a16 and w8a8.
Overview of RKLLM Runtime Features:
RKLLM Runtime is mainly responsible for loading the RKLLM models converted by RKLLM-Toolkit and implementing LLM model inference on the Rockchip NPU platform RK3576/RK3588 through NPU driver calls. When inferring LLM models, users can define the inference parameter settings of RKLLM models, define different text generation methods, and continuously obtain inference results through pre-defined callback functions.
¶ Introduction to RKLLM Development Process
The overall development process of RKLLM mainly consists of two parts: model conversion and board deployment and operation.
1.Model conversion:
During this stage, Hugging Face format LLMs provided by users will be converted to RKLLM format for efficient inference on the Rockchip NPU platform.
This step includes:
-
Obtain the original model: Obtain the Hugging Face format LLM or self-trained LLM, which requires the model’s saved structure to be consistent with the model structure on the Hugging Face platform.
-
Model loading: Load the original model using the rkllm.load_huggingface() function.
-
Model quantization configuration: Build the RKLLM model through the rkllm.build() function. During the building process, users can choose whether to quantize the model to improve the performance of model deployment on hardware, as well as select different optimization levels and quantization types.
-
Model export: Export the RKLLM model to a .rkllm format file using the rkllm.export_rkllm() function for subsequent deployment.
2.Board deployment and operation: This stage covers the actual deployment and operation of the model. It usually includes the following steps:
-
Model initialization: Load the RKLLM model to the Rockchip NPU platform, perform corresponding model parameter settings to define the desired text generation method, and pre-define callback functions to receive real-time inference results for inference preparation.
-
Model inference: Perform inference operations by passing input data to the model and running model inference. Users can continuously obtain inference results through pre-defined callback functions.
-
Model release: After completing the inference process, release the model resources to allow other tasks to continue using the NPU’s computing resources.
These two steps constitute the complete development process of RKLLM, ensuring successful conversion, debugging, and efficient deployment of large language models on the Rockchip NPU.
¶ Applicable Hardware Platforms
This document applies to hardware platforms mainly including: RK3576, RK3588
¶ Development Environment Preparation
In the released RKLLM toolchain compressed file, it includes the RKLLM-Toolkit’s whl installation package, related files of RKLLM Runtime library, and reference example code. The specific folder structure is as follows:
doc
└──Rockchip_RKLLM_SDK_EN.pdf # RKLLM SDK documentation
rkllm-runtime
├──example
│ └── src
│ └── main.cpp
│ └── build-android.sh
│ └── build-linux.sh
│ └── CMakeLists.txt
│ └── Readme.md
├──runtime
│ └── Android
│ └── librkllm_api
│ └──arm64-v8a
│ └── librkllmrt.so # RKLLM Runtime library
│ └──include
│ └── rkllm.h # Runtime header file
│ └── Linux
│ └── librkllm_api
│ └──aarch64
│ └── librkllmrt.so
│ └──include
│ └── rkllm.h
rkllm-toolkit
├──examples
│ └── huggingface
│ └── test.py
├──packages
│ └── md5sum.txt
│ └── rkllm_toolkit-1.0.0-cp38-cp38-linux_x86_64.whl
rknpu-driver
└──rknpu_driver_0.9.6_20240322.tar.bz2In this chapter, detailed instructions will be provided on the installation of RKLLM-Toolkit tools and RKLLM Runtime. For specific usage methods, please refer to the instructions in Chapter 3.
¶ Installation of RKLLM-Toolkit
This section mainly explains how to install RKLLM-Toolkit through pip. Users can follow the specific process instructions below to complete the installation of the RKLLM-Toolkit toolchain.
Installation via pip
Install miniforge3 tool
To avoid the system’s requirement for multiple different versions of Python environments, it is recommended to use miniforge3 to manage Python environments. Check whether miniforge3 and conda versions are installed. If installed, this step can be omitted.
conda -V
# If conda is not installed, it will prompt "conda: command not found"
# If conda is installed, it will show the version, for example, conda 23.9.0Download the miniforge3 installation package
wget -c https://mirrors.bfsu.edu.cn/github-release/condaforge/miniforge/LatestRelease/Miniforge3-Linux-x86_64.shInstall miniforge3
chmod 777 Miniforge3-Linux-x86_64.sh
bash Miniforge3-Linux-x86_64.shCreate RKLLM-Toolkit Conda environment
Enter the Conda base environment
source ~/miniforge3/bin/activate # miniforge3 is the installation directory
# (base) xxx@xxx-pc:~$Create a Conda environment named RKLLM-Toolkit with Python 3.8 version (recommended version)
conda create -n RKLLM-Toolkit python=3.8Enter the RKLLM-Toolkit Conda environment
conda activate RKLLM-Toolkit
# (RKLLM-Toolkit) xxx@xxx-pc:~$Installation of RKLLM-Toolkit
Install the RKLLM-Toolkit toolchain whl package directly using pip in the RKLLM-Toolkit Conda environment. During the installation process, the installation tool will automatically download the necessary dependencies for the RKLLM-Toolkit tools.
pip3 install rkllm_toolkit-1.0.0-cp38-cp38-linux_x86_64.whlIf the following commands execute without errors, the installation is successful.
python
from rkllm.api import RKLLM¶ Usage of RKLLM Runtime Library
The released RKLLM toolchain files include all files containing RKLLM Runtime:
-
lib/librkllmrt.so: RKLLM Runtime library for RK3576/RK3588 board-side deployment and inference of RKLLM models.
-
include/rkllm_api.h: Header file corresponding to librkllmrt.so function library, which includes explanations of related structures and function definitions.
When building deployment and inference code for RK3576/RK3588 boards through the RKLLM toolchain, attention should be paid to linking the above header files and function libraries to ensure correct compilation. When the code is actually running on RK3576/RK3588 boards, it is also necessary to ensure that the above function library files are successfully pushed to the board and declare the function library through the following environment variables:
ulimit -Sn 50000
export LD_LIBRARY_PATH=./lib
./llm_demo qwen.rkllm¶ Compilation Requirements of RKLLM Runtime
During the use of RKLLM Runtime, attention should be paid to the version issue of the gcc compiler. It is recommended to use the cross-compilation tool gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu. The specific download path is: .
Please note that cross-compilation tools are often downward compatible but not upward compatible, so do not use versions below 10.2.
If you choose to use the Android platform, you need to compile Android executable files. It is recommended to use the Android NDK tool for cross-compilation. The download path is: Android NDK Cross Compilation Tool Download Address, and the recommended version is r18b.
Specific compilation methods can also refer to example/build_demo.sh in the RKLLM-Toolkit toolchain files.
¶ Chip Kernel Update
Since the current publicly available firmware kernel driver version does not support the RKLLM tool, it is necessary to update the kernel. The rknpu driver package supports two main kernel versions: kernel-5.10 and kernel-6.1. For kernel-5.10, it is recommended to use a specific version number 5.10.198, repo: GitHub - rockchip-linux/kernel at develop-5.10; for kernel-6.1, it is recommended to use a specific version number 6.1.57. The specific version number can be confirmed in the Makefile under the kernel root directory. The update steps are as follows: a. Download the compressed package rknpu_driver_0.9.6_20240322.tar.bz2. b. Unzip the package and overwrite the rknpu driver code in the current kernel code directory. c. Recompile the kernel. d. Burn the newly compiled kernel into the device.
¶ DeepSeek support
¶ Way 1 : DeepSeek- R1 RK35XX Deployment
-
Download the DeepSeek - R1 - 1.5B HunggingFace model
Create a new directory and download all the files here : https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B/tree/main
-
Write a conversion script and place it in the DeepSeek model directory.
from rkllm.api import RKLLM
from datasets import load_dataset
from transformers import AutoTokenizer
from tqdm import tqdm
import torch
from torch import nn
import os
# os.environ['CUDA_VISIBLE_DEVICES']='1'
modelpath = '.'
llm = RKLLM()
# Load model
# Use 'export CUDA_VISIBLE_DEVICES=2' to specify GPU device
# options ['cpu', 'cuda']
ret = llm.load_huggingface(model=modelpath, model_lora = None, device='cpu')
# ret = llm.load_gguf(model = modelpath)
if ret!= 0:
print('Load model failed!')
exit(ret)
# Build model
dataset = "./data_quant.json"
# Json file format, please note to add prompt in the input,like this:
# [{"input":"Human: 你好!\nAssistant: ", "target": "你好!我是人工智能助手KK!"},...]
qparams = None
# qparams = 'gdq.qparams' # Use extra_qparams
#ret = llm.build(do_quantization=True, optimization_level=1, quantized_dtype='w8a8',
# quantized_algorithm='normal', target_platform='rk3588', num_npu_core=3, extra_qparams=qparams, dataset=dataset)
ret = llm.build(do_quantization=True, optimization_level=1, quantized_dtype='w8a8',
quantized_algorithm='normal', target_platform='rk3576', num_npu_core=2, extra_qparams=qparams, dataset=dataset)
if ret!= 0:
print('Build model failed!')
exit(ret)
# Evaluate Accuracy
def eval_wikitext(llm):
seqlen = 512
tokenizer = AutoTokenizer.from_pretrained(
modelpath, trust_remote_code=True)
# Dataset download link:
# https://huggingface.co/datasets/Salesforce/wikitext/tree/main/wikitext - 2 - raw - v1
testenc = load_dataset(
"parquet", data_files='./wikitext/wikitext - 2 - raw - 1/test - 00000 - of - 00001.parquet', split='train')
testenc = tokenizer("\n\n".join(
testenc['text']), return_tensors="pt").input_ids
nsamples = testenc.numel() // seqlen
nlls = []
for i in tqdm(range(nsamples), desc="eval_wikitext: "):
batch = testenc[:, (i * seqlen): ((i + 1) * seqlen)]
inputs = {"input_ids": batch}
lm_logits = llm.get_logits(inputs)
if lm_logits is None:
print("get logits failed!")
return
shift_logits = lm_logits[:, :-1, :]
shift_labels = batch[:, 1:].to(lm_logits.device)
loss_fct = nn.CrossEntropyLoss().to(lm_logits.device)
loss = loss_fct(
shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
neg_log_likelihood = loss.float() * seqlen
nlls.append(neg_log_likelihood)
ppl = torch.exp(torch.stack(nlls).sum() / (nsamples * seqlen))
print(f'wikitext - 2 - raw - 1 - test ppl: {round(ppl.item(), 2)}')
# eval_wikitext(llm)
# Chat with model
messages = "<|im_start|>system You are a helpful assistant.<|im_end|><|im_start|>user你好!\n<|im_end|><|im_start|>assistant"
kwargs = {"max_length": 128, "top_k": 1, "top_p": 0.8,
"temperature": 0.8, "do_sample": True, "repetition_penalty": 1.1}
# print(llm.chat_model(messages, kwargs))
# Export rkllm model
ret = llm.export_rkllm("./deepseek - r1.rkllm")
if ret!= 0:
print('Export model failed!')
exit(ret)
If you need to perform accuracy evaluation, download the dataset as per the code and do the accuracy evaluation. If you need to adjust the quantization strategy, modify it accordingly above. Execute this script, and you can get the converted model deepseek - r1.rknn.
Deployment and running on the development board (write a development board program based on rkllm_api)
#include <cstdio>
#include <cstdint>
#include <cstdlib>
#include <cstring>
#include <string>
#include <iostream>
#include <fstream>
#include <vector>
#include <csignal>
#include "rkllm.h"
#define MODEL_PATH "/data/deepseek - r1_3588_w8a8.rkllm"
LLMHandle llmHandle = nullptr;
void exit_handler(int signal) {
if (llmHandle!= nullptr)
{
{
std::cout << "The program is about to exit" << std::endl;
LLMHandle _tmp = llmHandle;
llmHandle = nullptr;
rkllm_destroy(_tmp);
}
}
exit(signal);
}
void callback(RKLLMResult *result, void *userdata, LLMCallState state) {
if (state == RKLLM_RUN_FINISH) {
printf("\n");
} else if (state == RKLLM_RUN_ERROR) {
printf("\\run error\n");
} else if (state == RKLLM_RUN_GET_LAST_HIDDEN_LAYER) {
/* ================================================================================================================
If the GET_LAST_HIDDEN_LAYER function is used, the callback interface will return the memory pointer: last_hidden_layer, the number of tokens: num_tokens, and the hidden layer size: embd_size.
The data in last_hidden_layer can be obtained through these three parameters.
Note: It needs to be obtained in the current callback. If not obtained in time, the next callback will release the pointer.
===============================================================================================================*/
if (result->last_hidden_layer.embd_size!= 0 && result->last_hidden_layer.num_tokens!= 0) {
int data_size = result->last_hidden_layer.embd_size * result->last_hidden_layer.num_tokens * sizeof(float);
printf("\ndata_size:%d",data_size);
std::ofstream outFile("last_hidden_layer.bin", std::ios::binary);
if (outFile.is_open()) {
outFile.write(reinterpret_cast<const char*>(result->last_hidden_layer.hidden_states), data_size);
outFile.close();
std::cout << "Data saved to output.bin successfully!" << std::endl;
} else {
std::cerr << "Failed to open the file for writing!" << std::endl;
}
}
} else if (state == RKLLM_RUN_NORMAL) {
printf("%s", result->text);
}
}
int main() {
signal(SIGINT, exit_handler);
printf("rkllm init start\n");
// Set parameters and initialize
RKLLMParam param = rkllm_createDefaultParam();
param.model_path = MODEL_PATH;
// Set sampling parameters
param.top_k = 1;
param.top_p = 0.95;
param.temperature = 0.8;
param.repeat_penalty = 1.1;
param.frequency_penalty = 0.0;
param.presence_penalty = 0.0;
param.max_new_tokens = 128000;
param.max_context_len = 128000;
param.skip_special_token = true;
param.extend_param.base_domain_id = 0;
int ret = rkllm_init(&llmHandle, ¶m, callback);
if (ret == 0){
printf("rkllm init success\n");
} else {
printf("rkllm init failed\n");
exit_handler(-1);
}
std::string text;
RKLLMInput rkllm_input;
// Initialize the infer parameter structure
RKLLMInferParam rkllm_infer_params;
memset(&rkllm_infer_params, 0, sizeof(RKLLMInferParam)); // Initialize all contents to 0
rkllm_infer_params.mode = RKLLM_INFER_GENERATE;
while (true)
{
std::string input_str;
printf("\n");
printf("user: ");
std::getline(std::cin, input_str);
if (input_str == "exit")
{
break;
}
text = input_str;
rkllm_input.input_type = RKLLM_INPUT_PROMPT;
rkllm_input.prompt_input = (char *)text.c_str();
printf("robot: ");
// If you want to use the normal inference function, configure rkllm_infer_mode to RKLLM_INFER_GENERATE or do not configure parameters
rkllm_run(llmHandle, &rkllm_input, &rkllm_infer_params, NULL);
}
rkllm_destroy(llmHandle);
return 0;
}Execute command
ulimit -Sn 50000
export LD_LIBRARY_PATH=.
cd ~
chmod 777 llm_demo
./llm_demo deepseek-r1.rkllm 10000 1000¶ Way 2 : DeepSeek - R1 RK35XX Deployment
-
Download the DeepSeek - R1 - 1.5B HunggingFace model
-
Create a new directory and download all the files here : https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B/tree/main
¶ Model Transformation
Firstly, we need to create the rkllm model with data_quantit.json for quantization. We will use the fp16 model to generate the results as quantization calibration data. Secondly, run the following code to generate data_quant. json and export the rkllm model.
cd rknn-llm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/export
python generate_data_quant.py -m /path/to/DeepSeek-R1-Distill-Qwen-1.5B
python export_rkllm.pyIf it is a 3576 development board, it is necessary to modify export_rkllm. py
target_platform = "RK3576"
num_npu_core = 2After execution, the .rkllm model file will be generated in the directory
¶ C++ demonstrate
In the deploy directory, there is example code for board side inference
cd rknn-llm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy
# for linux
./build-linux.sh
# for android
./build-android.sh
# push install dir to device
adb push install/demo_Linux_aarch64 /data
# push model file to device
adb push DeepSeek-R1-Distill-Qwen-1.5B-rk35**.rkllm /data/demo_Linux_aarch64Before running the script, it is necessary to modify the compiler position of the development board For example:
GCC_COMPILER_PATH=~/customized_project/3576/rk3576_linux_rkr5/linux/prebuilts/gcc/linux-x86/aarch64/gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu¶ Run demonstration
Example of running a directory on the /data/demo_Linux_arch64 board
adb shell
cd /data/demo_Linux_aarch64
# export lib path
export LD_LIBRARY_PATH=./lib
taskset f0 ./llm_demo ./DeepSeek-R1-Distill-Qwen-1.5B_W8A8_RK3576.rkllm 2048 4096|
1,If you copy from the demo, remove the scene prompt words. DeepSeek does not need prompt words. 2,Pay attention to the Chinese character encoding of the input in the terminal. 3,The development board memory needs to be 8G or more, and it occupies about 70% during operation. |
|
1.If you copy from the demo, remove the scene prompt words. DeepSeek does not need prompt words. 2.Pay attention to the Chinese character encoding of the input in the terminal. 3.The development board memory needs to be 8G or more, and it occupies about 70% during operation. |
¶ Usage Environment
Development board: BPI-M7 ,BPI-M5 Pro, BPI-AIM7,BPI-AIM6,BPI-CM5 Pro
repository: https://github.com/ArmSoM/rknn-llm